Richmond Bridge bike path opening
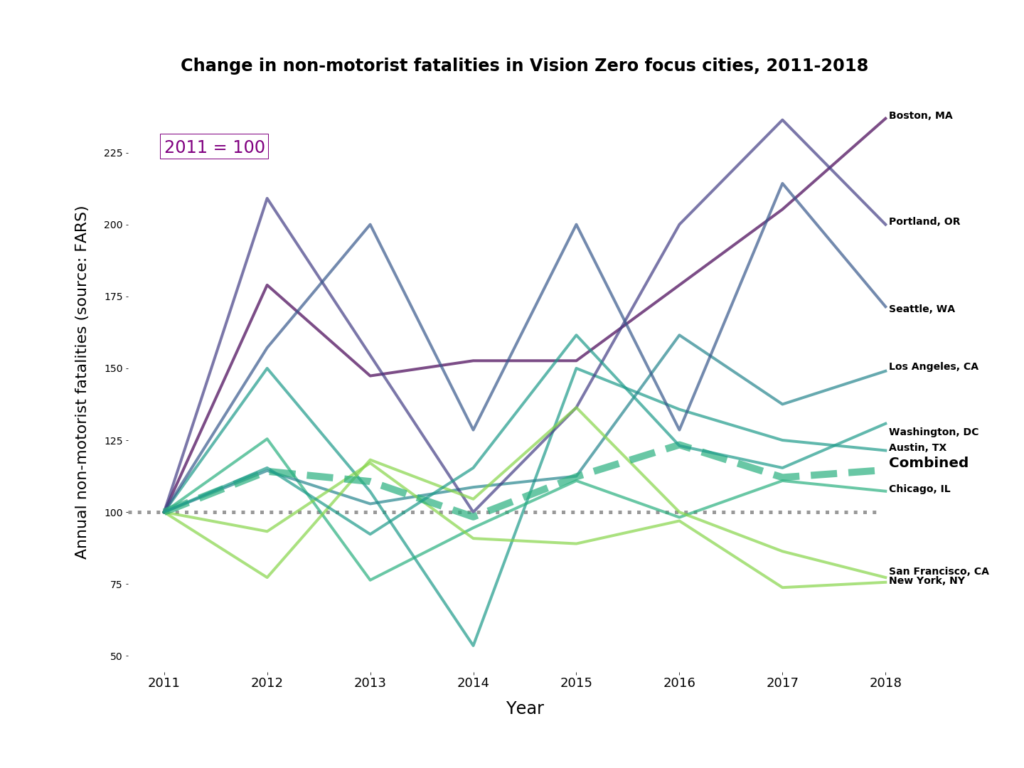
The big event this weekend was the opening of the Richmond Bridge bike path. Najari killed it with his remarks at the ribbon-cutting, and I enjoyed the path more than I expected to. A lot of that was the energy of the event, where there were at least 1,000 cyclists. The few times where I was riding more or less solo, the isolation and noise of the bridge felt a bit oppressive; I think on an average day noise and smell will be real issues. But it’s better than another car lane.