
I’ve been working on generalizing my code so that I can make comparisons for dozens (or hundreds) of cities. And of course, I’ve found a ton of bugs, mostly related to my own poor understanding of Python data structures and functions. I’ve been able to speed up the code by at least an order of magnitude, which makes running it at scale a lot more feasible.
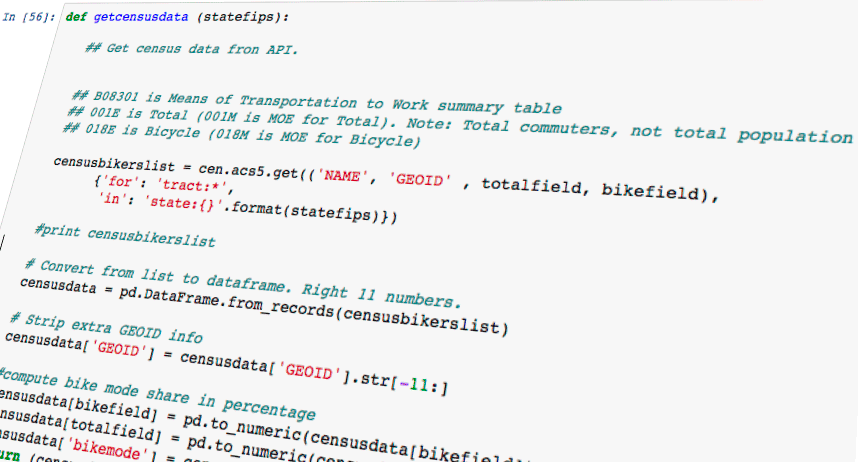
But in addition to performance bugs, I found a fundamental issue with the calculations I used in my thesis. (Shh…don’t tell my adviser.) I had calculated residential density based on the B08301 summary table of the 2015 ACS 5-year estimates, by dividing the 018E field by 001E. 018E is the number of cyclists, and 001E is the total number. That sounds like density, right? Except 001E is the total number of commuters, not the total number of residents. So my findings, which made statements about the relationship of residential density to bike commuting, were a bit off.
The percentage of total commuters is how bike mode share is calculated, so the calculation I was using is still important. And we don’t have good data on non-work cycling trips, so residents who don’t work (or work from home) can’t be counted as part of those who might take commute trips. Still, I need to be clear about what I’m describing. And I’ll probably pull in total population data also; now that I have the API working it’s pretty easy.

